


Commercial Wedges for Bio-Foundation Models
Framing AI opportunities in the biology economy

TLDR;
Its 2024. The AI races are in full swing. Where is AI practically useful in biology? The purpose of this short essay is to create a framing for LLMs and other classes of foundation models in medicine. We explore how we can wedge classes of foundation models into the complex supply chain of our biology economy.
Key Takeaways from the AI race in 2024
In 2018, OpenAI released GPT-1, its legacy 117 million parameter model. At that time, the power of the large language model was hardly newsworthy. 6 years later, with GPT-4o-mini, a 1+ trillion parameter multi-modal model, the world is fundamentally a different place.

We not only have intelligence, but we also have commoditized suites of tools and services like Gemini’s Google Search integration, Anthropic’s inference-caching, and open-sourced Llama 3 code. What’s clear in 2024 is that the AI race is an indication of significant and rapid commoditization of many characteristics of human intelligence: summarizing information, searching for answers in documents, answering basic questions, coding, drafting emails, etc. In an interview with Noema Magazine, Eric Schmidt, the former CEO of Google, stated that we will shortly see infinite context windows, free inference of select highly-capable models, agentic workflows built for navigating the internet, and models integrated with cloud compute and data storage resources. There is a clear opportunity here to re-imagine what we think is possible for biology.
The (Growing) Universe of Foundation Models
The AI hype does not seem to be slowing down, but we can group the LLMs into one of many families of models that are useful for biology and healthcare. It is important to be aware of what LLMs fundamentally are not and how other classes of bio-foundation models would serve wildly different purposes.
Large Language Models: Traditional foundation models are useful as quick assistive human-esque inference for many types of medical professions.
Large Language Model Applications: Tooling embedded with LLM-native workflows will more seamlessly aid quick assistive human-esque inference.
Physics and Simulation Models: Protein-folding simulation models like AlphaFold-3 are wildly different from LLMs. These models are based against physics ground truth and experiments like X-ray crystallography techniques for protein structure reconstitution. Many sub-cellular and cellular level interaction predictions in biology could benefit with their own models like these. However, the training data required to validate such models might be far more complex and expensive to acquire (in contrast to natural language data for LLMs).
Computer Vision Models: Biology has lots of 2D image and 3D video data captured and labeled — imaging techniques like MRIs, x-rays, CT scans, fluorescence-based microscopy, tradition histology stains are widely used throughout medicine. The object segmentation learnings from other industries means the “analysis work” done by humans looking at these types of images can be shifted to programatic model inference.

How can we think about Wedges for Bio-Foundation Models
While Large Language Models and Computer Vision Models are two different families of models, they are both great mechanisms for substituting discrete tasks of human-esque inference in the medical supply chain. The way they can be packaged up as inference products queryable by simple APIs make them well-suited for commercial distribution. While physics and simulation models are similar in that regard, they are very different in their underlying utility. I like to think of these bio-foundation models as fundamental in-silico representations of cellular and sub-cellular biology. They are foundational prediction tools that can chip away at expensive wet-lab hypothesis testing. If these models can help us predict small molecule off-target effects, protein-protein binding affinity, amino acid sequence substitution effects, or even cell-therapy introduction effects, we can start to run massively parallel inference that serve as rapid in-silico hypothesis testing. Real-world testing is why medicine is so hard and expensive. These types of bio-foundation models can preserve wet-lab testing for highly precise shots on target — which would save the industry a ton of resources.

Framing Bio-Foundation Model Wedges
The biology economy has two major landscapes with discrete wedges — the pharmaceutical development pipeline and specialty-specific clinical flows. In the pharmaceutical development pipeline, markets can be picked off by experimental stage, where addressable markets are concrete and established. In specialty-specific clinical flows, commercial wedges might include the markets for diagnostics, interventions and human-in-the-loop administrative work-streams. For example, in oncology, these wedges might include immune microenvironment inference analysis from histology stains or genetic-variant patient-matching to ongoing clinical trials.
The Pharmaceutical Gantt Chart

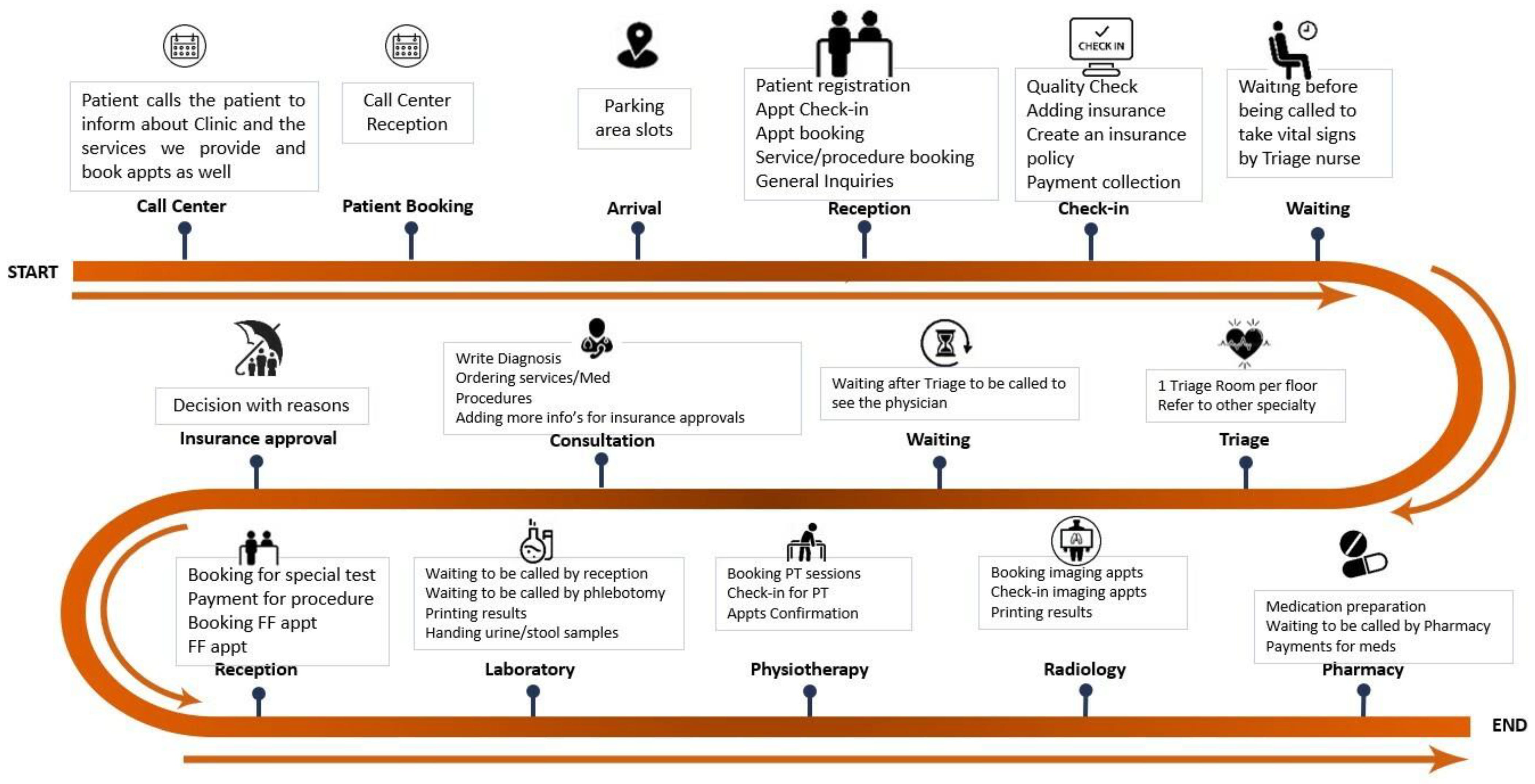
Specialty-specific clinical flows
That’s a Wrap!
Thanks for reading.
Amazing article as always! Very interesting on using LLMs for each anatomy part and great visuals